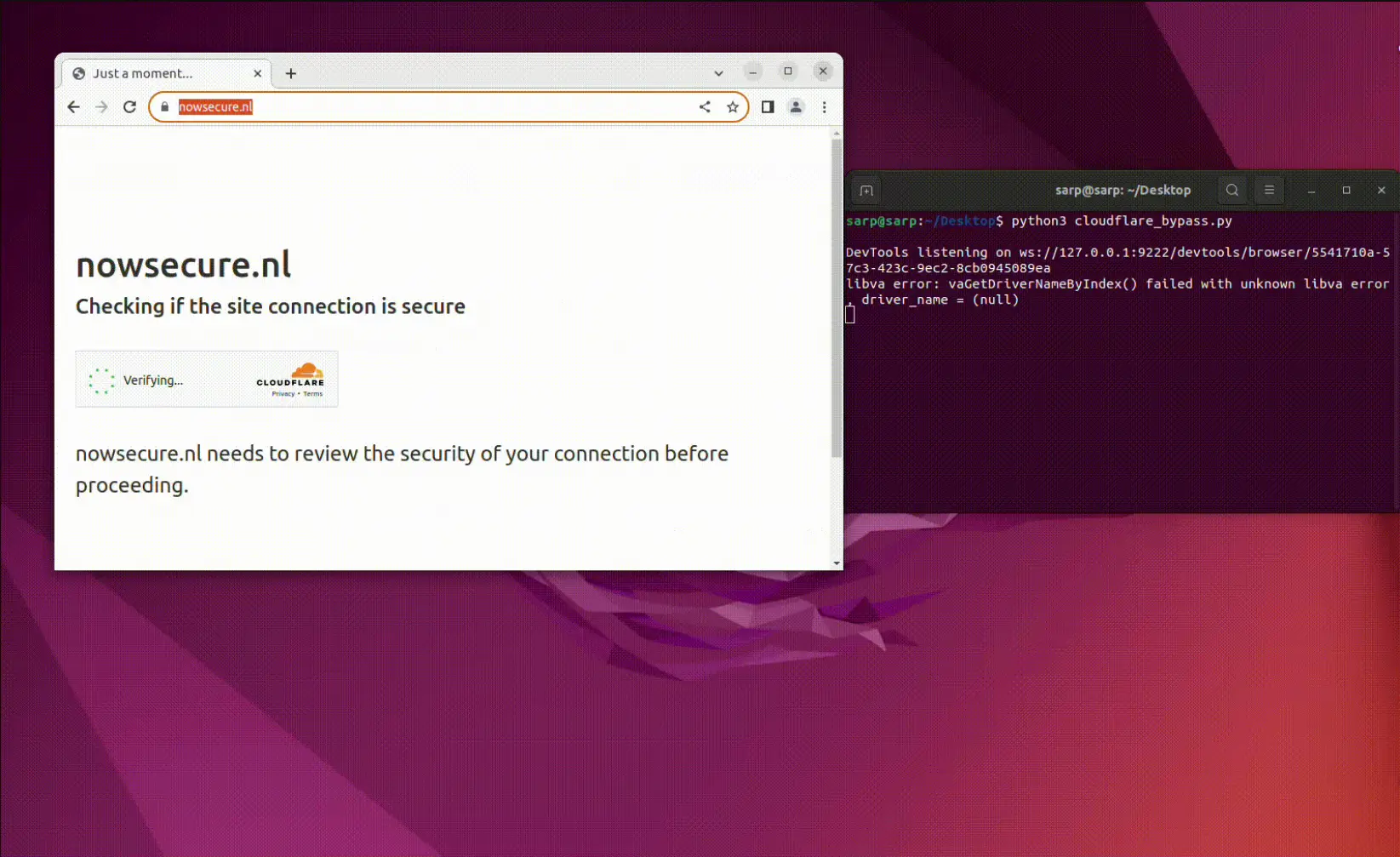
cloudflare验证绕过脚本CloudflareBypassForScraping
此 Python 脚本专为教育目的而设计,演示了与受 Cloudflare 保护的网站交互的基本方法。请负责任地使用此脚本,并且仅在您拥有适当授权的网站上使用。
先决条件
在运行脚本之前,请确保已安装以下先决条件:
https://www.python.org/
Pythonhttps://www.chromium.org/getting-involved/download-chromium/
Chromium 浏览器(或 Chrome)安装
将此存储库克隆到您的本地计算机:
git clone https://github.com/sarperavci/CloudflareBypassForScraping.git导航到项目目录:
cd CloudflareBypassForScraping安装所需的 Python 包:
pip install -r requirements.txt用法
编辑脚本以指定您想要交互的网站的 URL,并且不要忘记更改文件中的 browser_path(第 17 行)。它可以在 Windows 和 Linux 上运行,无需 webdriver。它直接与浏览器一起使用:
# Change this line to your desired website URL driver.get('https://example.com')运行脚本:
python cloudflare_bypass.py该脚本将尝试绕过 Cloudflare 保护并与指定网站进行交互。请耐心等待,因为可能需要一些时间才能完成。确保仅在您有明确授权的网站上使用此脚本。
脚本演示

DrissionPage
要了解如何使用 DrissionPage(我在此脚本中将其用作控制器),请查看它的文档。确保在阅读时使用英文翻译,否则会更困难:D
https://github.com/g1879/DrissionPage
官方文档http://g1879.gitee.io/drissionpagedocs/
文档化免责声明
该脚本仅用于教育目的。未经授权使用此脚本绕过安全措施(包括 Cloudflare)可能会违反法律和道德准则。在与网站交互之前,请务必获得适当的授权。
项目地址
https://github.com/sarperavci/CloudflareBypassForScraping
GitHub直链下载地址
https://lp.lmboke.com/CloudflareBypassForScraping-main.zip
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 程序员小航
阅读建议





评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果