CanaryTokenScanner 金丝雀令牌扫描器
CanaryTokenScanner简介
旨在识别 Microsoft Office 文档和 Acrobat Reader PDF(docx、xlsx、pptx、pdf)中的 Canary 令牌。
检测 Microsoft Office、Acrobat Reader PDF 和 Zip 文件中的 Canary 令牌和可疑 URL。
介绍
在网络安全的动态领域,保持警惕和主动防御是关键。恶意行为者经常利用 Microsoft Office 文件和 Zip 存档,嵌入隐蔽 URL 或宏来发起有害操作。此 Python 脚本旨在通过检查 Microsoft Office 文档、Acrobat Reader PDF 文档和 Zip 文件的内容来检测潜在威胁,从而降低无意触发恶意代码的风险。
脚本原理
鉴别
该脚本可以智能识别 Microsoft Office 文档(.docx、.xlsx、.pptx)、Acrobat Reader PDF 文档(.pdf)和 Zip 文件。这些文件类型(包括 Office 文档)是可以通过编程方式检查的 zip 存档。
解压扫描
对于 Office 和 Zip 文件,该脚本会将内容解压缩到临时目录中。然后,它使用正则表达式扫描这些内容中的 URL,寻找潜在的妥协迹象。
忽略某些 URL
为了最大限度地减少误报,该脚本包含一个要忽略的域列表,过滤掉 Office 文档中常见的常见 URL。这可确保集中分析异常或潜在有害的 URL。
标记可疑文件
URL 不在忽略列表中的文件将被标记为可疑。这种启发式方法可以根据您的特定安全上下文和威胁情况进行适应性调整。
清理和恢复
扫描后,脚本通过擦除临时解压缩文件进行清理,不留下任何痕迹。
用法
要有效地利用该脚本:
设置
确保您的系统上安装了 Python。
将脚本放置在可访问的位置。
使用以下命令执行脚本:(
python CanaryTokenScanner.py FILE_OR_DIRECTORY_PATH替换FILE_OR_DIRECTORY_PATH为实际文件或目录路径。)
解释
检查输出。请记住,此脚本是一个起点;标记的文档可能不会有害,并且并非所有恶意文档都会被标记。建议进行手动检查和额外的安全措施。
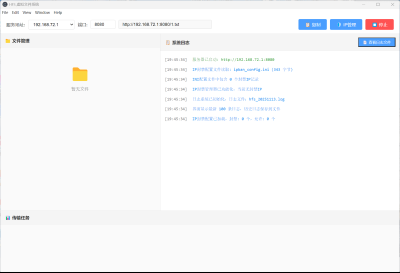
脚本展示
运行中的 Canary 令牌扫描程序脚本示例,展示了其检测可疑 URL 的能力。

免责声明
该脚本仅用于教育和安全测试目的。负责任地使用它并遵守适用的法律和法规。
项目地址
GitHub:
https://github.com/0xNslabs/CanaryTokenScanner直链下载地址
https://lp.lmboke.com/CanaryTokenScanner-main.zipCanaryTokenScanner.py
import os
import zipfile
import re
import shutil
import sys
import zlib
from pathlib import Path
if len(sys.argv) != 2:
print("Usage: python script.py FILE_OR_DIRECTORY_PATH")
sys.exit(1)
FILE_OR_DIRECTORY_PATH = sys.argv[1]
def extract_urls_from_stream(stream):
try:
decompressed_data = zlib.decompress(stream)
urls = re.findall(b'https?://[^\s<>"\'{}|\\^`]+', decompressed_data)
return urls
except zlib.error:
return []
def process_pdf_file(pdf_path):
with open(pdf_path, 'rb') as file:
pdf_content = file.read()
streams = re.findall(b'stream[\r\n\s]+(.*?)[\r\n\s]+endstream', pdf_content, re.DOTALL)
found_urls = []
for stream in streams:
urls = extract_urls_from_stream(stream)
if urls:
found_urls.extend(urls)
return found_urls
def decompress_and_scan(file_path):
is_suspicious = False
temp_dir = "temp_extracted"
os.makedirs(temp_dir, exist_ok=True)
try:
with zipfile.ZipFile(file_path, 'r') as zip_ref:
zip_ref.extractall(temp_dir)
url_pattern = re.compile(r'https?://\S+')
ignored_domains = ['schemas.openxmlformats.org', 'schemas.microsoft.com', 'purl.org', 'w3.org']
for root, dirs, files in os.walk(temp_dir):
for file_name in files:
extracted_file_path = os.path.join(root, file_name)
with open(extracted_file_path, 'r', errors='ignore') as extracted_file:
contents = extracted_file.read()
urls = url_pattern.findall(contents)
for url in urls:
if not any(domain in url for domain in ignored_domains):
print(f"URL Found in {file_path}:\n{url}")
is_suspicious = True
except Exception as e:
print(f"Error processing file {file_path}: {e}")
finally:
shutil.rmtree(temp_dir, ignore_errors=True)
return is_suspicious
def is_suspicious_file(file_path):
if file_path.lower().endswith(('.zip', '.docx', '.xlsx', '.pptx')):
return decompress_and_scan(file_path)
elif file_path.lower().endswith('.pdf'):
urls = process_pdf_file(file_path)
if urls:
print(f"The file {file_path} is suspicious. URLs found:")
for url in urls:
print(url.decode('utf-8', 'ignore').replace('/QXUGUTAENT)', ''))
return True
return False
def main():
if os.path.exists(FILE_OR_DIRECTORY_PATH):
if os.path.isfile(FILE_OR_DIRECTORY_PATH):
if is_suspicious_file(FILE_OR_DIRECTORY_PATH):
print(f"The file {FILE_OR_DIRECTORY_PATH} is suspicious.")
else:
print(f"The file {FILE_OR_DIRECTORY_PATH} seems normal.")
elif os.path.isdir(FILE_OR_DIRECTORY_PATH):
for root, dirs, files in os.walk(FILE_OR_DIRECTORY_PATH):
for file_name in files:
current_file_path = os.path.join(root, file_name)
if is_suspicious_file(current_file_path):
print(f"The file {current_file_path} is suspicious.")
else:
print(f"The file {current_file_path} seems normal.")
else:
print(f"The path {FILE_OR_DIRECTORY_PATH} does not exist.")
if __name__ == "__main__":
main()